As you may be aware, we had an outage for a fair amount of our infrastructure from 2026-04-23T22:45 until 2026-04-24T04:02 and this post will try to break down what happened and what was done to fix the situation.
All times are specified in UTC.
What happened
Around 2026-04-23T22:00 I started deploying a an instance of the limnoria IRC bot to our Kubernetes cluster on DigitalOcean and ran into issues which was surprising because it is a pretty standard deployment but has a volume for storage.
The problem was that the volume could not be mounted to the Kubernetes node where the pod got scheduled. I was getting the follow error that didn’t make any sense.
error attaching volume to droplet: droplet and allocation are not in the same region
I’ve seen something similar with Amzon EKS so I thought maybe something went weird on my end. I kept digging for about an hour but didn’t find anything. But then I noticed at 2026-04-24T22:45 that there was an update for the Kubernetes cluster for DigitalOcean specific changes. Thinking this may fix the problem I went ahead and started the upgrade.
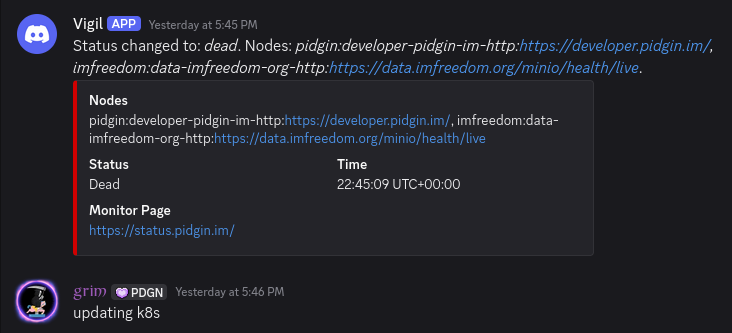
The upgrade went more or less as expected, except every single deployment that included a volume was failing to start, and this was the start of the outage. This was clearly not my fault, as many of these deployments, including their volumes were created six years ago. This included our ci.imfreedom.org, data.imfreedom.org, xmpp.pidgin.im, xmpp.imfreedom.org, and xmpp.pidginchat.com.
Response
After I realized what was happening I started looking to see if there was mention of an outage, but their status page didn’t show anything.
In the past I had gotten support from them via the digitalocean-k8s channel on the Kubernetes Slack so I jumped in there to ask. However, that channel seems to not be used much at all anymore as the last message was from 2026-01-06.
So I dig around and finally find how to create a ticket with DigitalOcean support. This wasn’t really hard, I just haven’t done it before. Anyways, we don’t pay for a support plan because we’re a volunteer run Open Source project and don’t exactly have the money to pay for that.
The free plan says they’re respond within 24 hours. That’s not great when you’re down, but it’s something. I went ahead and created the ticket at 2026-04-24T23:35 with as much information as I could and then had to wait.
Resolution
At 2026-04-24T01:08 DigitalOcean support responded and confirmed the issue and that it was not isolated to a single workload or PVC and escalated it to their engineering team.
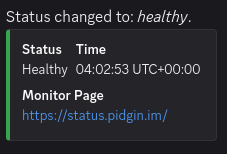
At 2026-04-24T04:02 our service monitoring determined everything to be healthy. I went and verified as soon as I noticed, and everything was back up.
DigitalOcean support replied at 2026-04-24T08:30 stating an update from their engineering team:
This was related to a bug in Block storage public API; we’ve deployed a rollback and the cluster is in good shape now.
We were of course already aware of this, but it was nice to get a follow up. I responded with a confirmation that everything was working and closed the ticket.
However, I still don’t see any mention of an outage from this in their incident history so that isn’t ideal.
What could have been done better
So there’s not a much different that I could have done here as this was ultimately a DigitalOcean issue that affected us. However, I could have tried restarting an existing deployment that isn’t as impactful as our XMPP server to confirm the issue before restarting everything.
In the future, I think I just need to be a bit more cautious when it comes to restarting everything in the cluster, but since there wasn’t a known outage this kind of a decision is basically a coin flip. Regardless, being more cautious is general a safe bet.